
Active Data Repository Accelerates Access to Large Data Sets
From: NPACI & SDSC Envision, April-June 1998
PR0JECT LEADER
JOEL SALES
Professor, Department of Computer Science and Institute for Advanced Computer Studies, University of Maryland; Associate Professor, Department of Pathology The Johns Hopkins University Medical Institutions; Leader, Programming Tools & Environments Thrust Area, NPACI
TO STUDY POLLUTION AND WAYS TO REDUCE IT IN BAYS AND ESTUARIES, Mary Wheeler and her colleagues at the University of Texas have constructed a two-part simulation: The first part models shallow water flowing along coastlines, and the second part models chemicals reacting and moving in water. However, linking the two supercomputer simulations is not a simple job. The chemical transport part depends on the water flow (or hydrodynamics), but the chemical transport simulation uses different time scales and model grids. Even if it were simple to store and retrieve output of the hydrodynamics model, a single step from the chemical transport simulation needs to average the output from several steps of the hydrodynamics simulation.
A standard database can only store and retrieve individual hydrodynamic snapshots. A more efficient approach would let the database average the snapshots and perform other basic processing. Through NPACI, the Active Data Repository (ADR) project at the University of Maryland is providing the capabilities needed by Wheeler's pollution remediation scenario and many other scientific applications (Figure 1).
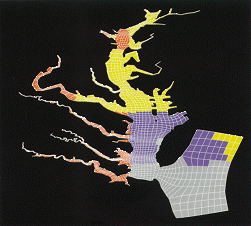 FIGURE 1: CHESAPEAKE BAY SIMULATION
FIGURE 1: CHESAPEAKE BAY SIMULATION
This simulation of the Chesapeake Bay region by the University of Texas Bays and Estuaries Simulator (UTBEST) is based on an unstructured Godunov-type finite-volume method. Colors denote the distribution across four processors of the domain elements, devised to minimize the costs of communications among processors. |
"Most relational and object-oriented databases provide little or no support for processing the data stored in them," said Joel Saltz, professor in the Department of Computer Science and the Institute for Advanced Computer Studies (UMIACS) at the University of Maryland and the leader of NPACI's Programming Tools and Environments thrust area. "The assumption is that the processing will be too application-specific to warrant common support."
The ADR project, led by Saltz, integrates data retrieval with processing, because many scientific applications have similar processing requirements, at least for formatting data returned from a database.
Integrated processing has three main advantages. First, because the ADR runs on high-performance parallel machines, the processing step can use the high-end hardware. Second, by overlapping processing and retrieval, ADR can mask query latencies and improve efficiency. Without parallelism, operations can take up to twice as long. Finally, ADR minimizes the amount of data transmitted from server to client because the processed data is often much smaller than the amount of data accessed.
"The constraints are that we get to choose the order of processing," said Alan Sussman, research scientist, Maryland's Computer Science Department and UMIACS, who is working on the ADR project with Saltz and doctoral candidate Chialin Chang. "The processing operations can't depend on the order data is retrieved"
The constraints, however, still permit many common data manipulations: transforming input items, mapping from one grid to another, aggregating items by averaging, and computing subsamples and other statistical winnowing methods. The ADR can be customized for various applications, while the system provides a uniform interface to the data and processing. An application developer need only provide a data description and the processing methods.
Typically, the processing for an ADR query happens in three steps. First, individual data objects are pre-processed with a transform function. Then the objects are mapped from the input attribute set to the output attribute set. Finally, an aggregation function computes an output item Tom the set of input items that map to it.
The ADR currently runs on a 16-node IBM SP at Maryland with the data sets stored on up to 64 disks. Plans call for moving the ADR server to NPACI's 128-node IBM SP at SDSC and extending the ADR to use tape archives, such as the High Performance Storage System (HPSS) at SDSC. Applications will require both the larger machine and larger storage system to manage full-scale data sets.
SATELLITES AND MICROSCOPES
The ADR has been or is being applied to projects in geography, medicine, and environmental science to demonstrate its generality for accessing large, multidimensional data sets. "We've done the work to make sure everything happens in parallel in a high-performance environment," Sussman said.
The first ADR application was implemented as part of a Grand Challenge project on land cover classification led by Larry Davis, professor in the Department of Computer Science and UMIACS, and geographers at Maryland. With a database of overlapping images from the Advanced Very High Resolution Radiometer (AVHRR) satellite, Joseph JàJà, director of UMIACS, and colleagues used the ADR to analyze global land cover. "A long-term scenario is for a user to search, cross-correlate, and mine distributed Earth system data, collected from multiple sensors and archived automatically,' JàJà said.
A typical query in this application might ask for the land cover of a particular country or region, specifying a time frame and resolution. From the query, the ADR develops a plan of action. First, the spatial query is mapped to segments of the relevant AVHRR images. Then the data is processed with methods for AVHRR correction and land cover analysis before being returned.
A second collaboration, with researchers from Johns Hopkins University, created a "virtual microscope" (Figure 2). High-resolution images were digitized from biological slides with a high-powered microscope; a single slide could require 50 gigabytes to store. A client application then uses the ADR to view each slide at low magnification (by subsampling the high-resolution image) and to zoom in on specific regions at higher magnifications. Such an application would allow physicians to compare specimens with earlier cases from their own institutions or a global collection of digitized cases.
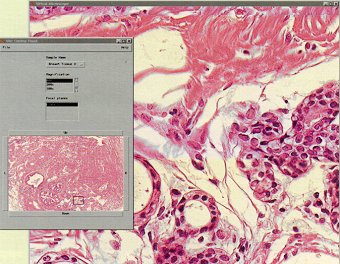 FIGURE 2: A VIRTUAL MICROSCOPE
FIGURE 2: A VIRTUAL MICROSCOPE
Researchers at Maryland and Johns Hopkins used the capabilities of the Active Data Repository to create a microscope-like interface for a database of digitized specimen slides. |
The collaboration with Wheeler's group at Texas came about through NPACI. The bay and estuary simulation effort, between the Earth Systems Science and Programming Tools and Environments thrust areas, is linking different models to simulate complex physical phenomena more accurately.
Accurate simulations of the transport and reaction of pollutants in surface water must include not only chemical reaction information but also water flow information. But combining both flow and chemical calculations in the same simulation comes with a heavy computational price. The basic fluid flow in a bay or estuary does not change, even though pollution may enter in many ways, perhaps as non-point fertilizer runoff or as an oil spill. In a combined simulation, hydrodynamic data must be recomputed for every new pollution scenario.
By separating the two aspects, Wheeler's group can save time by computing and storing water depth, flow velocities, and turbulence information of the 3-D bay or estuary model only once. In fact, they are using two different programs, ADCIRC and UT-BEST, to perform the flow simulations. The pollution simulation, CE-QUAL-ICM, looks up the hydrodynamic flow in the ADR.
"Coupling the two simulators to form a complete system is not a straightforward process for several reasons," Wheeler said. Primarily, the coupling must account for differences in time scale and grid resolution. The chemical transport model can examine changes over days or over hundreds of years, using time steps that are out of sync with the hydrodynamics simulation or need the average of several flow steps. A separate code, UT-PROJ, must map the hydrodynamics grid to the chemical transport grid.
Under NPACI, the Texas group is parallelizing the simulation codes and working with the ADR group to optimize the storage of hydrodynamic simulator output. The Maryland group is working with Wheeler to define a data dictionary for such data, create the customized processing components, and incorporate them into the ADR.
"With the bay and estuary simulation, we are gaining experience in determining how much help we have to provide developers," Sussman said. "The goal is eventually to have the developers take advantage of the ADR in their own applications and write all their own components." -DH
http://www.cs.umd.edu/projects/hpsl/Chaos.htm
Sites & Affiliations | Leadership | Research & Applications | Major Accomplishments | FAQ | Search | Knowledge & Technology Transfer | Calendar of Events | Education & Outreach | Media Resources | Technical Reports & Publications | Parallel Computing Research Quarterly Newsletter | News Archives | Contact Information
| Hipersoft | CRPC |
© 2003 Rice University
|